In the world of software engineering, high-level system design (HLD) is the art of zooming out. While low-level design focuses on class hierarchies, logic, and specific code snippets, HLD is concerned with the macroscopic view of a system. It defines how data flows, how components interact, and how a platform survives under the weight of millions of concurrent users.
For backend developers, mastering HLD is the transition point from being a feature developer to becoming a system architect. It requires an understanding of infrastructure, networking, and the inherent trade-offs between consistency, availability, and partition tolerance.
1. Introduction to High-Level System Design
High-level system design serves as the blueprint for an entire application ecosystem. Think of it as the master plan of a city. Before you decide what color to paint the walls of a single house (the code), you must determine where the highways go, where the power plants are located, and how the water supply reaches every neighborhood. In technical terms, this involves selecting the right database engines, determining where to place caches, and deciding how to distribute incoming traffic across multiple servers. The goal of HLD is to ensure that the system is scalable, reliable, and maintainable.
An effective HLD does not just list components; it explains the relationships between them. It addresses non-functional requirements such as latency, throughput, and fault tolerance. In a production environment, HLD acts as a communication tool between stakeholders, DevOps engineers, and developers, ensuring everyone understands the constraints and capabilities of the platform they are building.
2. Why HLD Diagrams Matter in System Design Interviews
In a system design interview, the diagram is your most powerful weapon. It is often the first thing an interviewer looks at to judge your technical maturity. A clean HLD diagram demonstrates that you can think about a problem holistically. It shows that you aren’t just thinking about the “happy path” where everything works, but that you are considering edge cases, bottlenecks, and points of failure.
Interviewers use HLD diagrams to probe your knowledge of trade-offs. For example, if you place a cache in your diagram, they will ask about your eviction policy. If you show a load balancer, they will ask about its distribution algorithm. The diagram provides a visual anchor for the conversation, allowing you to walk the interviewer through the lifecycle of a request. A messy or incomplete diagram often leads to a disorganized interview, whereas a structured, logical diagram allows you to drive the conversation and showcase your expertise in scaling complex systems.
3. The Core Components of a High-Level System
To build a robust system, we need a standard set of building blocks. Each component plays a specific role in ensuring the application remains responsive and data remains consistent.
Users and CDN
The journey begins with the Users. They interact with the system via web browsers or mobile apps. To reduce latency for these users, we employ a Content Delivery Network (CDN). A CDN is a geographically distributed group of servers that cache static content like images, CSS, and JavaScript files near the user’s location. By serving static assets from the “edge,” we significantly reduce the load on our primary application servers and improve the user experience.
Load Balancer
As traffic moves past the CDN, it hits the Load Balancer (LB). The LB is the gatekeeper. Its job is to distribute incoming network or application traffic across a number of backend servers. This prevents any single server from becoming a bottleneck and ensures high availability. If one server goes down, the load balancer stops sending traffic to it and reroutes requests to healthy instances. Common algorithms include Round Robin, Least Connections, and IP Hash.
Application Servers
The Application Servers are the brain of the system. This is where the business logic resides. In a modern HLD, these are typically stateless, meaning they don’t store user session data locally. This statelessness allows us to scale horizontally by simply adding more server instances as demand increases. They process requests, communicate with the cache and database, and return responses to the user.
Redis Cache
To optimize performance, we use Redis Cache. Database queries are expensive and slow. By storing frequently accessed data (like user profiles or session information) in-memory with Redis, we can retrieve it in microseconds. This drastically reduces the latency of read-heavy applications and protects the database from being overwhelmed by repetitive queries.
Message Queue
Not every task needs to happen immediately. A Message Queue (MQ), such as Kafka or RabbitMQ, allows for asynchronous processing. For example, when a user signs up, sending a welcome email doesn’t need to happen before the response is sent back to the user. We can push a message to the MQ, and a background worker can process it later. This improves system responsiveness and decouples different services.
Database Cluster (Primary + Read Replica)
The Database Cluster is the source of truth. To handle high traffic, we use a Primary-Replica architecture. The Primary Database handles all write operations (INSERT, UPDATE, DELETE). These changes are then asynchronously replicated to Read Replicas. This setup allows us to scale read operations almost indefinitely by adding more replicas, while keeping the primary database focused on data integrity and writes.
Monitoring System
Finally, a Monitoring System (like Prometheus and Grafana) is essential. It tracks the health of all components, monitoring CPU usage, memory, request latency, and error rates. Without monitoring, you are flying blind; you won’t know the system has failed until the users start complaining.
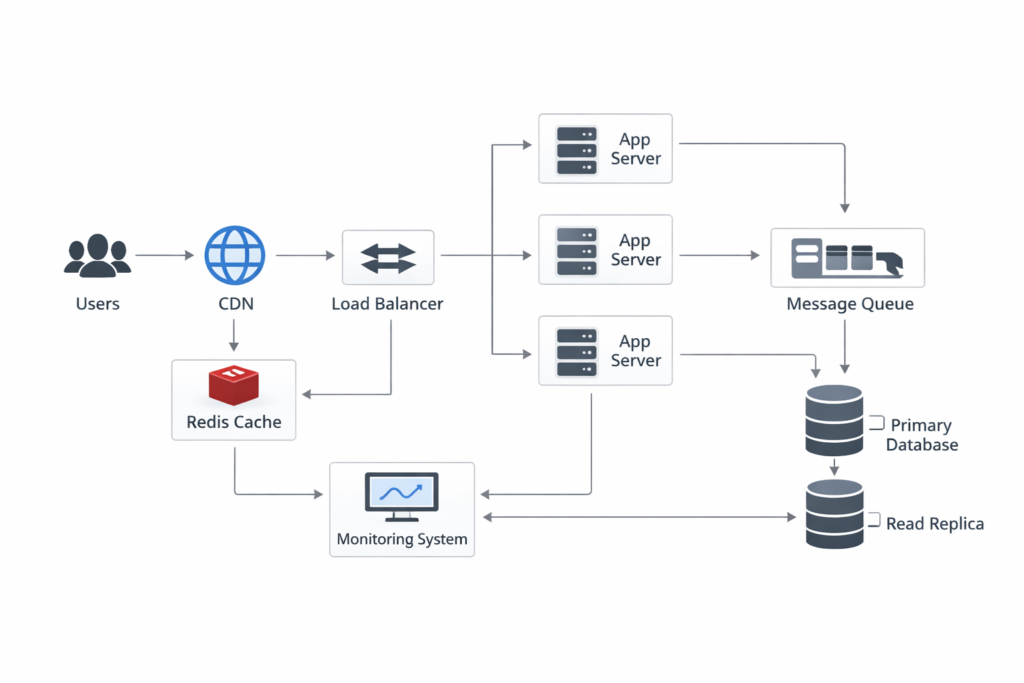
4. Request Flow Explanation (Step-by-Step)
Understanding how these components interact is best achieved by following a single request through the system. Let’s trace a standard GET request for a user profile:
- Step 1: The user enters a URL. The request first checks the CDN for any cached static assets. If the request is for dynamic data, it proceeds to the Load Balancer.
- Step 2: The Load Balancer receives the request and selects an available Application Server based on its internal logic.
- Step 3: The Application Server receives the request. It first checks the Redis Cache to see if the user profile data is already there. If it is (a cache hit), it returns the data immediately.
- Step 4: If the data is not in the cache (a cache miss), the server queries the Read Replica Database.
- Step 5: Once the data is retrieved from the database, the server updates the Redis Cache so the next request will be faster.
- Step 6: If the request involved a side effect (like logging an analytics event), the server pushes a message to the Message Queue for background processing.
- Step 7: The Application Server sends the final HTML or JSON response back through the Load Balancer to the user.
5. Scaling Strategy
Scaling is the core challenge of system design. There are two primary ways to scale: Vertical and Horizontal. Vertical scaling (adding more RAM/CPU to a single server) has a hard limit and creates a single point of failure. Therefore, HLD focuses on Horizontal Scaling.
For the application tier, we use Auto-scaling Groups that spin up new server instances based on CPU utilization. For the data tier, we use Database Sharding if the dataset becomes too large for a single primary node. Sharding involves splitting the data across multiple database instances based on a shard key (e.g., User ID). Additionally, Caching Strategies like “Cache Aside” or “Write-Through” are employed to manage how data moves between the application, cache, and database to ensure we don’t serve stale data while maintaining high performance.
6. Failure Handling
In a distributed system, failure is not a possibility; it is a certainty. A good HLD must be resilient. We implement Health Checks on the load balancer to automatically remove failing servers from the rotation. To handle database failure, we use Failover Mechanisms where a Read Replica is promoted to Primary if the original Primary goes offline.
We also use Circuit Breakers in our service communication. If a downstream service (like a third-party payment gateway) is slow or failing, the circuit breaker “trips,” and the system returns a default response or an error immediately rather than hanging and consuming resources. Retries with Exponential Backoff are used for transient network issues to ensure we don’t overwhelm a struggling service with a “thundering herd” of requests.
7. Interview Tips
When presenting an HLD in an interview, remember the following tips:
- Clarify Requirements First: Never start drawing until you know the scale (e.g., 10 million DAU) and the functional requirements.
- Start Simple: Draw the basic flow (User -> Server -> DB) before adding complex components like Message Queues or Caches. This shows you understand the core logic before optimization.
- Justify Every Component: Don’t just add Redis because it’s popular. Explain *why* you need it (e.g., to reduce DB read pressure).
- Discuss Trade-offs: Mention that while a CDN reduces latency, it introduces the challenge of cache invalidation.
8. Common Mistakes in HLD Diagrams
Many candidates fail because their diagrams are either too vague or too cluttered. A common mistake is ignoring the Single Point of Failure (SPOF). If your diagram has only one database and no replica, or one load balancer without a standby, you’ve created a system that can be taken down by a single hardware failure.
Another mistake is over-engineering. Don’t add a Message Queue if the system is simple and doesn’t require asynchronous processing. Interviewers look for “right-sized” solutions. Lastly, avoid vague arrows. Arrows should indicate the direction of data flow or the direction of the request. Labeling your arrows (e.g., “HTTPS,” “SQL,” “Pub/Sub”) adds a layer of professionalism that sets you apart.
9. Frequently Asked Questions
What is the difference between HLD and LLD?
HLD (High-Level Design) focuses on the system architecture, components, and data flow. LLD (Low-Level Design) focuses on the internal logic, class diagrams, and specific algorithms of those components.
When should I use a Message Queue?
Use a Message Queue when you have tasks that are time-consuming, can be processed asynchronously, or when you need to decouple services to handle spikes in traffic.
Is a Load Balancer always necessary?
For a small application with low traffic, a load balancer might be overkill. However, for any production system aiming for high availability and scalability, a load balancer is a mandatory component.
How do I choose between SQL and NoSQL in HLD?
Choose SQL (Relational) when you need ACID compliance and complex joins. Choose NoSQL (Non-relational) for massive scale, flexible schemas, or high-speed simple key-value lookups.
Mastering high-level system architecture is an iterative process that blends theoretical knowledge with practical experience. As you design more systems, you begin to see patterns and recognize that most large-scale applications share a common skeletal structure.
The components we discussed—from CDNs to database replicas—are the tools that allow us to build software capable of serving the entire world. By focusing on how these pieces fit together and constantly questioning the trade-offs of your design choices, you develop the intuition required to solve even the most daunting architectural challenges. Architecture is not about finding the perfect solution, but about finding the best set of compromises for the problem at hand, ensuring that as the world changes and your user base grows, your system remains a solid foundation for innovation.